그룹함수
AVG ([ DISTINCT | ALL ] n ) : Null값을 제외한 n의 평균 출력
SUM ([ DISTINCT | ALL ] n ) : Null값을 제외한 n의 합계 출력
MIN ([ DISTINCT | ALL ] expr ) : Null값을 제외한 expr의 최솟값을 출력
MAX ([ DISTINCT | ALL ] expr ) : Null값을 제외한 expr의 최댓값을 출력
COUNT ({ * | [ DISTINCT | ALL ] expr }) : 행의 수, expr은 Null값을 제외하고 계산
*를 사용하여 중복되거나 Null인 행들을 포함하여 모든 행을 계산
다음의 예시들을 통해 함수들이 어떻게 쓰이는지 확인해보자
1) AVG, MAX, MIN, SUM

아무래도 avg, mac, min, sum 함수들이 연산을 하는 함수들이다 보니 데이터가 숫자 형식이어야 한다
2) MAX, MIN - 날짜

날짜를 나타내는 hire_date를 min, max함수에 넣어 값을 구할 수 있다 (hire_date는 숫자 형식이기 때문)
그렇다면 문자 형식의 데이터는 완전 불가능한가?
3) MAX, MIN - 문자 형식

Nope!
avg나 sum함수 같은 경우는 연산이 필요하기 때문에 반드시 숫자 형식이어야 하나
min이나 max 함수는 데이터끼리 비교를 해서 결과를 도출하기에 문자 형식 데이터도 가능하다
COUNT ({ * | [ DISTINCT | ALL ] expr }) 함수

COUNT ( * ) : 중복되는 행과 null 값을 포함하는 행을 포함하여 테이블 행의 수를 리턴
COUNT (expr) : expr에 의해 인식된 열에서 Null 이 아닌 행의 수를 리턴
1. COUNT ( * ) 의 예시

' * ' 의미가 '모든 값을 출력'이기 때문에 중복되는 행이든 NULL값이든 상관없이 모두 포함한 행의 수를 반환
2. COUNT (expr) 의 예시


commission_pct라는 특정 열의 행의 수를 반환할 때
Null값이 아닌 데이터의 행의 수를 반환
만약 null값까지 모두 포함했다면 107이라는 숫자가 반환되었을 것!
GROUP BY 함수

GROUP BY절은
WHERE절 뒤에
ORDER BY절 앞에 사용
1. 하나의 열로 그룹화한 경우


SELECT department_id, AVG(salary) department_id열과 salary열을 평균낸 값을 출력해줘
FROM employees employees 데이터집합에서
GROUP BY deaprtment_id; employees테이블 속에 있는 department_id를 기준으로 그룹화해서
▶ department_id가 같은 데이터끼리 그룹을 지어서 그 그룹의 salary의 평균을 구해 출력
2. 하나 이상의 열로 그룹화한 경우


SELECT department_id, job_id, SUM(salary) department_id열과 job_id열과 salary열의 합계를 출력
FROM employees employees 데이터집합에서
GROUP BY department_id, job_id; employees에 있는 department_id와 job_id를 그룹화해서
▶ department_id가 같은 것끼리 그룹을 지은 다음 그 중에 job_id가 같은 것끼리 그룹을 지어서 salary 합계 출력
그룹함수를 이렇게 사용하면 절대 안 돼요!!
1. 그룹함수와 일반 열을 혼합해서 select할 경우

그룹 함수를 단독으로 사용할 때는 그룹화를 할 필요가 없으나
일반 열과 함께 사용할 때는 반드시 그룹화를 해야 한다
2. WHERE절에 그룹함수 사용하는 경우

그룹 함수는 WHERE절에 사용될 수 없고 제한을 주고 싶으면
HAVING절을 이용해야 한다(다음에 나옴!)
3. group by로 묶지 않은 칼럼은 select하는 경우

HAVING 함수

그룹화를 할 때 조건을 줘서
제한을 하기 위함이기 때문에
HAVING절은 GROUP BY절 다음에 사용
그룹화할 때 조건을 걸어서 제한을 두는 HAVING절, 다음의 예시로 자세하게 알아보자


1) SELECT department_id, ROUND(AVG(salary), 2)
department_id열과 salary열의 평균(단, 소숫점 두 번째 자리로 반올림)을 구해서 출력
FROM employees employees 데이터집합에서
GROUP BY department_id department_id를 기준으로 그룹을 지어서
HAVING AVG(salary) > 8000; 부서별로 구해진 salary의 평균이 8000이상인 부서들만 출력
2) SELECT job_id, AVG(salary) as PAYROLL
job_id열과 salary열의 평균을 구해서 출력하는데 PAYROLL이라는 별칭으로 불러줘
FROM employees employees 데이터집합에서
WHERE job_id NOT LIKE 'SA%' 근데 이제 job_id가 'SA'를 포함하지 않은 것만
GROUP BY job_id job_id를 기준으로 그룹을 지어서
HAVING AVG(salary) > 8000 job_id별 salary의 평균이 8000 초과인 것들만
ORDER BY AVG(salary); 급여의 평균을 기준으로 오름차순 정렬해서 출력
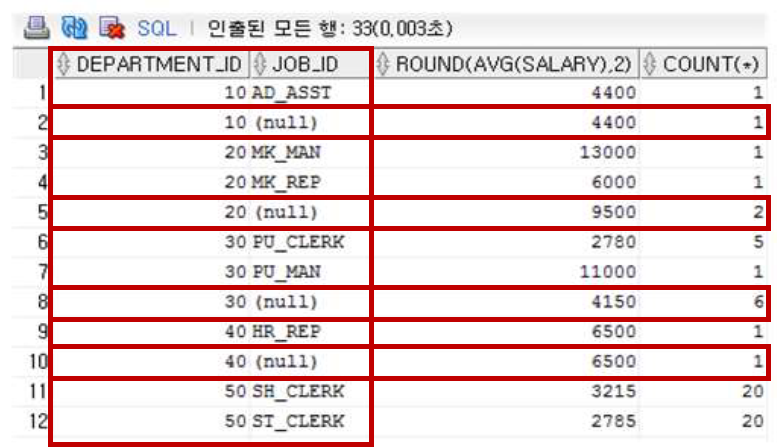
ROLLUP 함수
ROLLUP구문은 GROUP BY절과 같이 사용되며
GROUP BY 절에 의해서 그룹 지어진 집합 결과에 대해서 좀 더 상세한 정보를 반환하는 기능을 수행한다
SELECT절에 ROLLUP을 사용함으로써 보통의 SELECT된 데이터와 그 데이터의 총계를 구할 수 있음

department_Id가 같은 것끼리 그룹을 지은 다음에 그 내부에서 job_id로 한번 더 그룹화를 한다
다음의 데이터집합을 보면 (job_id가 (null)값으로 출력된 부분) 해당 데이터마다 총계를 출력해준다
(예를 들어 부서번호가 20인 부서의 총 급여 평균과 총 사원의 수 계산해서 출력해준다)
그리고 전체 급여 합계와 전체 사원 수를 계산해서 마지막에 출력해준다

CUBE 함수
CUBE는 서브 그룹에 대한 Summary 를 추출하는데 사용된다
(즉 ROLLUP에 의해 나타내어지는 Item Total 값과 Column Total 값을 나타 낼 수 있음)
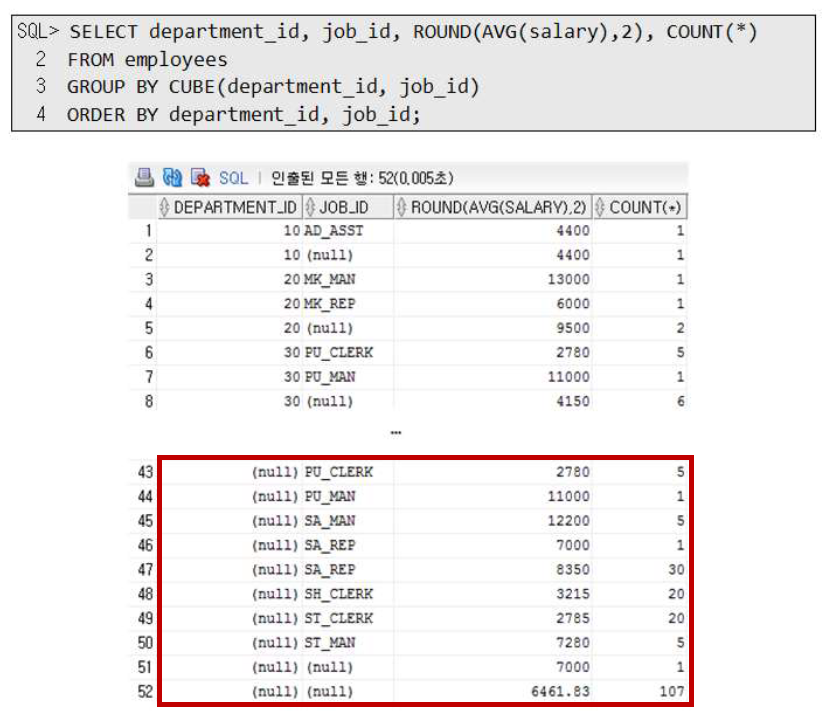
CUBE를 사용할 경우 ROLL UP에 의해 구해진 결과뿐 아니라
job_id(서브 그룹)에 대한 데이터의 총합을 추가로 구해준다
GROUPING 함수 : ROLLUP, CUBE에 모두 사용 가능
해당 Row가 GROUP BY에 의해서 산출된 Row 인 경우에는 0을 반환하고
ROLLUP이나 CUBE에 의해서 산출된 Row 인 경우에는 1을 반환하게 된다
다음의 예시를 확인해보면 보다 명확해질 것이다


SELECT
NVL2 ( department_id, department_id || ' ',
DECODE( GROUPING(department_id), 1, '소계' )) as 부서,
① DECODE( GROUPING(department_id), 1, '소계' ))
department_id열이 ROLL UP이나 CUBE에 의해 산출된 것이라면 1을 반환할 것이고,
GROUP BY에 의해 산출된 것이라면 0을 반환할 것이기기에
department_id가 1인 경우에 '소계'를 출력하도록 한다
** "(null)"로 출력된 것은 GROUP BY로 산출된 결과임을 알 수 있다
② NVL2 ( department_id, department_id || ' ', DECODE( GROUPING(department_id), 1, '소계' ))
department_id열이 null값이 아니라면 department_id에 공백을 추가하여 출력하고
null값이라면 DECODE함수가 실행된다
NVL( job_id,
DECODE( GROUPING(job_id), 1, '소계' )) as 직무,
① DECODE( GROUPING(job_id), 1, '소계' ))
job_id열이 무엇에 의해 산출된 데이터인지에 따라 1 또는 0이 반환이 될 것이고
만약 job_id열이 1을 반환한 경우 '소계'를 출력하도록 한다
② NVL( job_id, DECODE(GROUPING(job_id), 1, '소계' ))
job_id가 null값이 아니라면 job_id값을 그대로 출력하고
null값이라면 DECODE 함수가 시행된다
ROUND( AVG(salary), 2 ) as 평균,
COUNT ( * ) as 사원수
FROM employees
GROUP BY CUBE ( department_id, job_id )
주 그룹인 department_id의 총합뿐 아니라 서브그룹인 job_id의 총합도 출력
ORDER BY 부서, 직무;
< 연습문제 >
문제 1번

문제 2번

★ group by를 할 때 주의할 점 : 대상이 어떤 건지 정확하게 확인해야 한다
오늘의 티엠아이...
이 문제를 처음 풀 때는 hire_date만 group by를 해서 계속 순서가 이상하게 나왔다
알고 보니 하고자 하는 그룹이 hire_date(13/12/03처럼 저장되어 있는)가 아닌 hire_date를 문자열로 변환한 데이터를 그룹화하려고 하는 것이기 때문에 to_char(hire_date, 'YYYY"년"')를 대상으로 설정해야 하는 것이었다(정신 똑바로 차려라^^)
문제 3번

문제 4번

문제 5번

문제 6번

SELECT decode( grouping (department_id), 1, '합계', department_id) as department_id,
① grouping(department_id)
: department_id가 group by에 의해 산출되면 0으로 반환되고, rollup으로 산출되면 1로 반환
② decode( grouping (department_id), 1, '합계', department_id) as department_id
: department_id가 1이라면 '합계'를 산출하고 1이 아니라면 원래의 department_id값 산출
NVL( job_id, decode( grouping (job_id), 1, '소계')) as job_id,
: job_id가 null이 아니라면 원래의 job_id 데이터 값을 산출하고 null이라면 decode실행
count ( * ) as total,
sum( salary ) as sum
from employees
group by rollup (department_id, job_Id)
order by sum;
해서 안 되는 건 없다
'Oracle 기본 개념' 카테고리의 다른 글
| Oracle - 트랜잭션이란 무엇인가 (0) | 2022.11.21 |
|---|---|
| Oracle - DML (0) | 2022.11.20 |
| Oracle - 서브쿼리 (0) | 2022.11.15 |
| Oracle 함수의 모든 것 - 단일 행 함수 (0) | 2022.11.09 |
| Oracle이 Miracle이 되는 그 날까지 - SQL문 (0) | 2022.11.08 |



